
Permutation statistics are a form of empirical statistics where one modifies the data by permuting values that should be from the same distribution under the null hypothesis. For example, if we have error data about two versions of software A and B, then if there is no difference in error behaviour it should be possible to swop the error values between the data items and still have equally plausible data. This can be used to create many permuted datasets that can be compared with the original unpermuted data. If the orginal data lies to an extreme, then this suggests there is a difference between the software versions.
Also used in hcistats2e: Chap. 10: page 121
Also known as: permuted values
Used in glossary entries: empirical statistics, null hypothesis
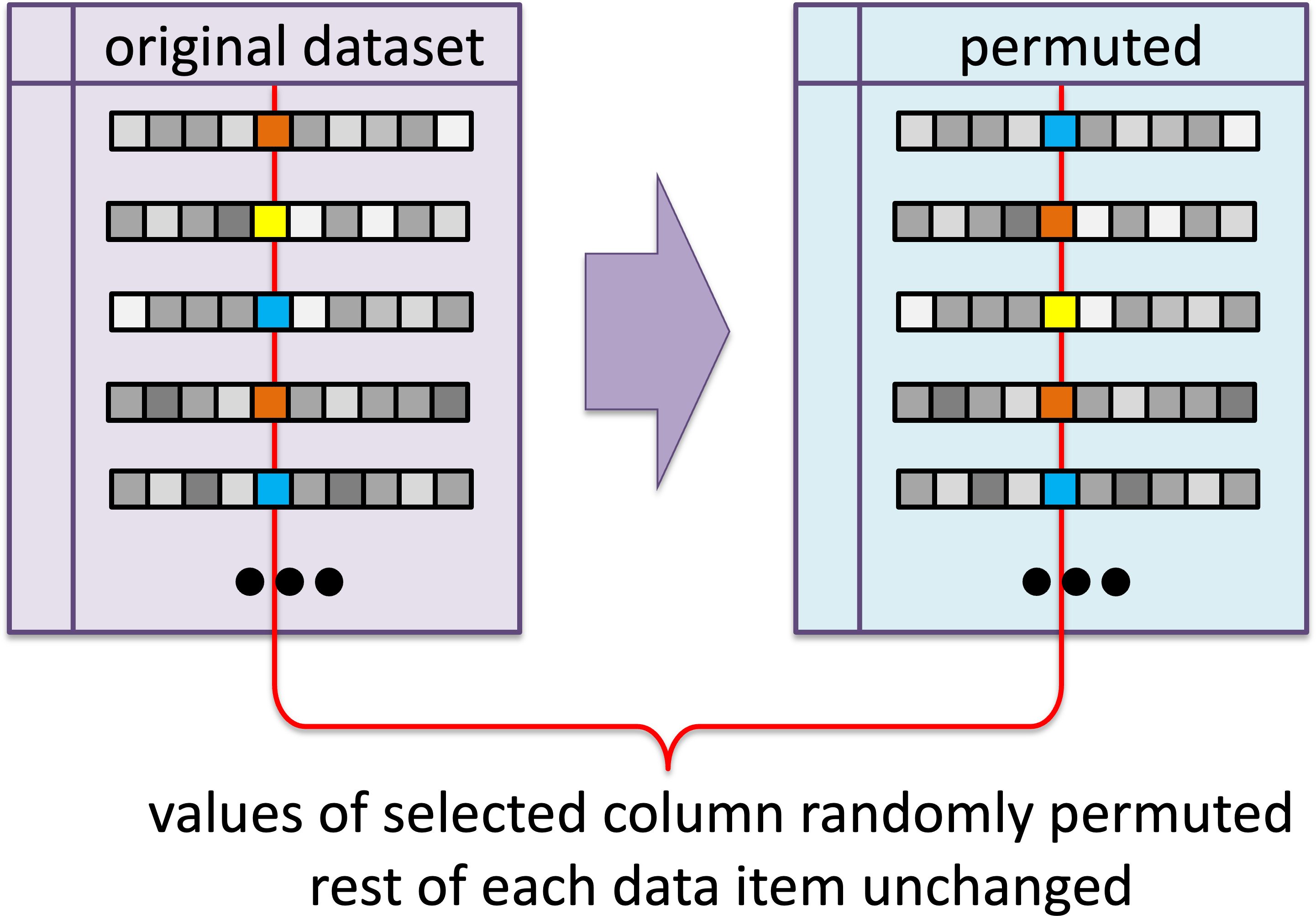
Figure 10.1: Different ways to generate new datasets. (ii) permuting values